Research
Introduction: SLAM is a technique for obtaining the 3D structure of an unknown environment and sensor motion in the environment. This technique was originally proposed to achieve autonomous control of robots in robotics. The SLAM-based applications have widely become broadened such as computer vision-based online 3D modeling, augmented reality (AR) / virtual reality (VR), and unmanned autonomous vehicles (UAV). Camera and LiDAR are the two main exteroceptive sensors used in SLAM for map modeling, which divided SLAM into two main subsets named Visual SLAM (V-SLAM) and LiDAR-based SLAM. Recently, deep learning has promoted the development of computer vision. The combination of deep learning and SLAM has attracted more and more attention. With the help of target detection, semantic segmentation, and high-level environmental information, SLAM can enable robots to better understand ego motion and the surrounding environment.
Details: multi-sensor fusion SLAM, dense tracking and mapping system, visual localization, point cloud place recognition, dense mapping, performance evaluation of robot localization with batural landmarks, visual localization, LiDAR place recognition, active view planning for feature and optimization-based visual SLAM, long-term SLAM, point cloud registration, navigation with scene graph prediction, 3D LiDAR mapping and stable navigation of designated routes
Introduction: In robotics, semantic scene understanding (SSU) refers to the interpretation and understanding of visual scenes in order for downstream robot tasks execution. It involves extracting high-level information from multiple types of sources, such as images, videos, point clouds, and natural language, and building contextual correspondences among elements within the information. Especially in our group, we tackle problems of scene graph generation, semantic rearrangement, semantic grasping, semantic mapping, active SLAM, and change detection. The ultimate goal is to endow robots with the ability to perceive and reason at the human level, and meanwhile interact with the unconstructed environment supported by the semantic knowledge. SSU is closely related to the concept of “Embodied AI”, but we are more interested in bringing SSU algorithms to real-world robotic applications.
Details: object relationship prediction for manipulation, Task-Oriented manipulation and grasping, scene change detection, tabletop rearrangement, indoor scene graph, navigation with scene graph prediction

Introduction: We are interested in developing robots capable of making interaction with human beings. This goal requires robots to have capabilities of low-level perception (sensing, detection, recognition and tracking) and high-level understanding (prediction and interaction). We dedicate to endowing robots with these abilities in two human-robot-interaction scenarios: robot person following (RPF) and task-aware manipulation. RPF is to endow a robot to follow its master accurately and persistently, which is a basic and vital function for many human-robot-interaction applications. We have developed a vision-based RPF system that can solve partial occlusion and target loss problems in complex environments. Currently, we focus on improving life-long person identification ability of the robot. Task-aware manipulation refers to a robot physically manipulating the environment to fulfill a designated task. The whole process often consists of task-aware grasp synthesis, task-aware manipulation trajectory planning, and path planning of a mobile base (optionally). We are currently developing a mobile manipulator system which is capable of traversing and manipulating unconstructed environments (e.g., apartment, office) according to humans’ natural language instructions (e.g., table setting, object retrieval).
Details: Task-Oriented manipulation and grasping, robot person following, orientation estimation for people following robot, robot navigation with social awareness, navigation with scene graph prediction

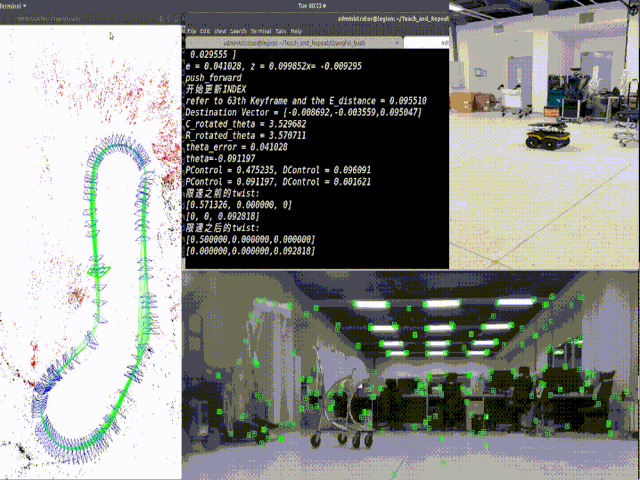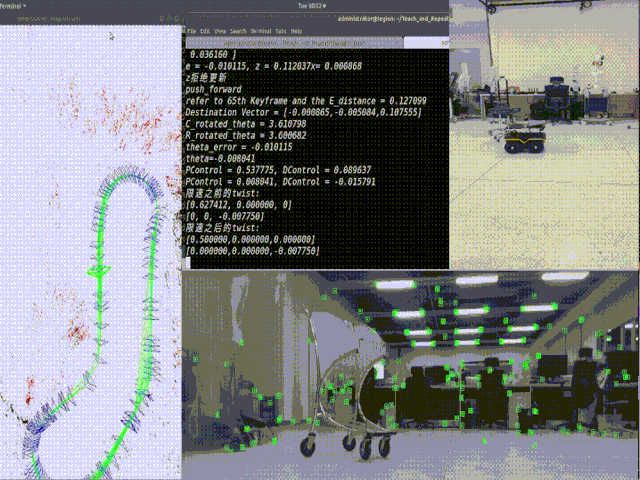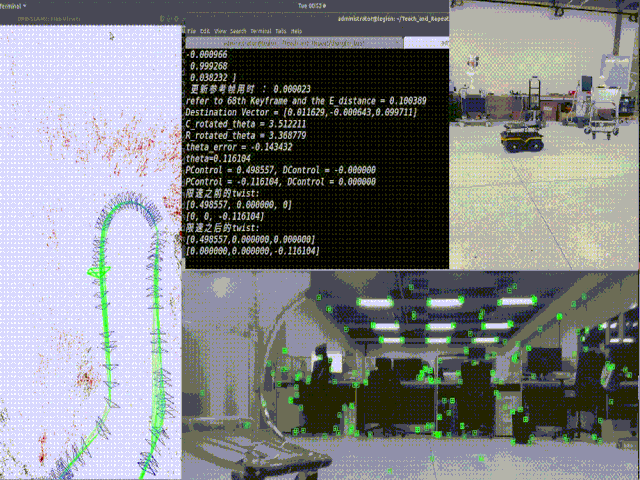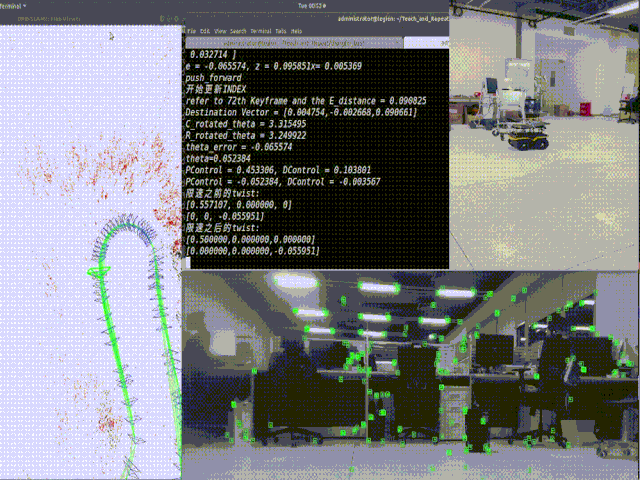
Introduction: We propose the perspective phase angle (PPA) model as a superior alternative to the orthographic phase angle (OPA) model for accurately utilizing polarization phase angles in 3D reconstruction with perspective polarization cameras. The PPA model also allows planar surface estimation from single-view polarization images. This model serves as the foundation of polarimetric 3D reconstruction.
Our current research of polarization centers around exploiting geometric cues of polarization for non-lambertian surfaces reconstruction and recognition, aiming to create reliable perception system for mobile robot. Non-lambertian including glass and smooth metal are still challenging to traditional passive sensors like RGB cameras, and active sensors like depth cameras. Polarization cameras provides compensated information for traditional sensors. Polarization is one of property of light. Unpolarized light can be polarized by transmission, reflection, scattering and refraction and the polarization phase angle depends on the geometries and materials of the polarizers. Therefore, polarization information provides extra cues for recovering the geometries and materials of surfaces.
Details: polarimetric 3D reconstruction